はじめに¶
このNotebookではVCP SDKを利用してVCノードを起動、削除する手順を記しています。
概要¶
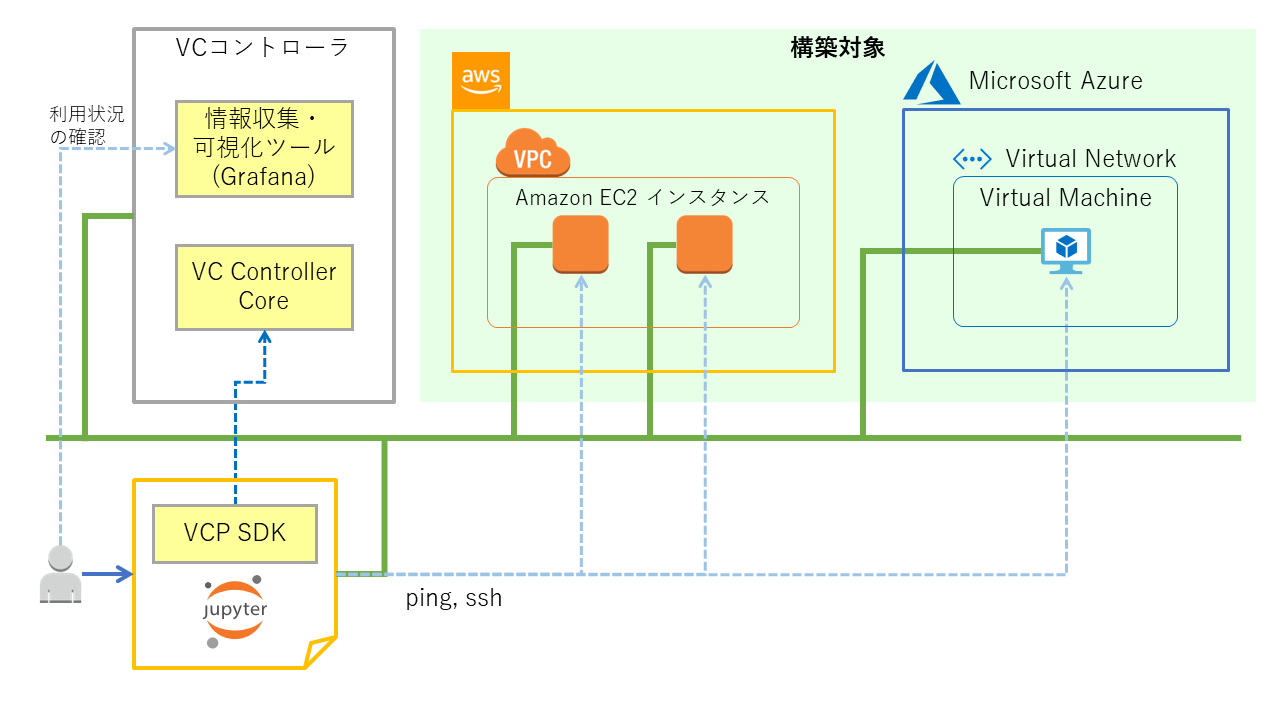
用語説明¶
上の図、またはこれ以降に示す図に記されている構成要素についての簡単な説明を以下に記します。
- VPC
- Amazon が提供している AWS 内の仮想プライベートネットワーク環境
- Amazon EC2
- Amazon が提供している仮想コンピューティング環境
- Azure Virtual Network
- Microsoft が提供しているクラウド内の仮想プライベートネットワーク環境
- Azure Virtual Machine
- Microsoft が提供している仮想コンピューティング環境
- VCコントローラ
- VCPが提供しているクラウド環境構築・管理のためのソフトウェアコントローラ
- VC Controller Core
- ユーザからのAPI呼び出しを受けとりUnitGroupの作成、削除などを行う
- 情報収集・可視化ツール(Grafana)
- 可視化ツール、ダッシュボードツール
- VCP では VCノード のモニタリング状況を表示するのに利用している
- VCP SDK
- VCPの機能を呼び出して VM/BM の作成、削除などを行うPython3のライブラリ
- VCノード
- Amazon EC2, Azure Virtual Machine などの計算資源を抽象化したVCPのノード
- Unit
- 同質(同じ計算資源(cpu, memory, ...)、同じクラウド、同じ用途、...)であるVCノードをまとめて扱うためのもの
- UnitGroup
- 複数のUnitをまとめて扱うためのものです
手順¶
大まかな手順は以下のようになります。
- VCノードの起動
- VCノードに ssh でログインして操作する
- 情報収集・可視化ツールでVCノードの利用状況を確認する
- VCノードのスケールアウト、スケールイン
- 別のクラウドでVCノードを起動する
- 全てのVCノードを削除する
アクセストークンの入力¶
VCP SDKを利用するにはVCコントローラのアクセストークンが必要となります。次のセルを実行すると入力枠が表示されるのでアクセストークンの値を入力してください。
アクセストークン入力後に Enter キーを押すことで入力が完了します。
from getpass import getpass
vcc_access_token = getpass()
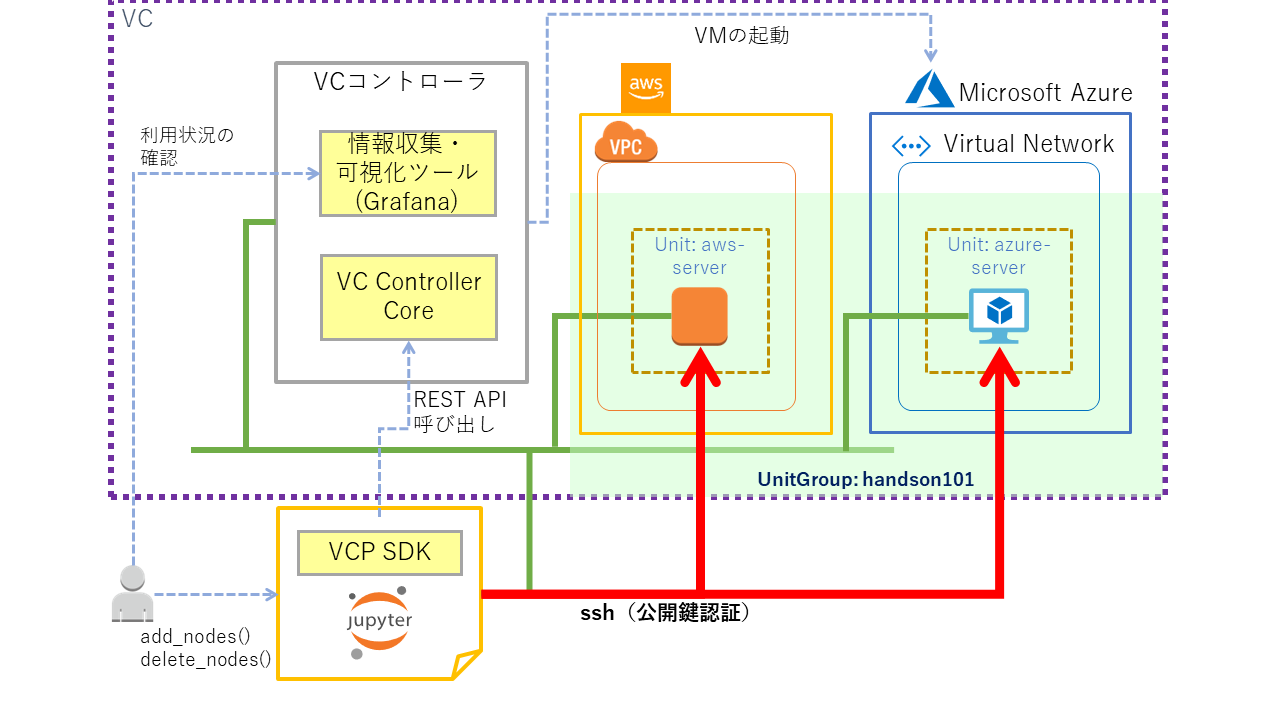
VCノードの起動¶
VCP SDKを用いてVCノード(Amazon EC2インスタンス)を起動します。また、起動したVCノードに対してsshでログインして操作を行います。
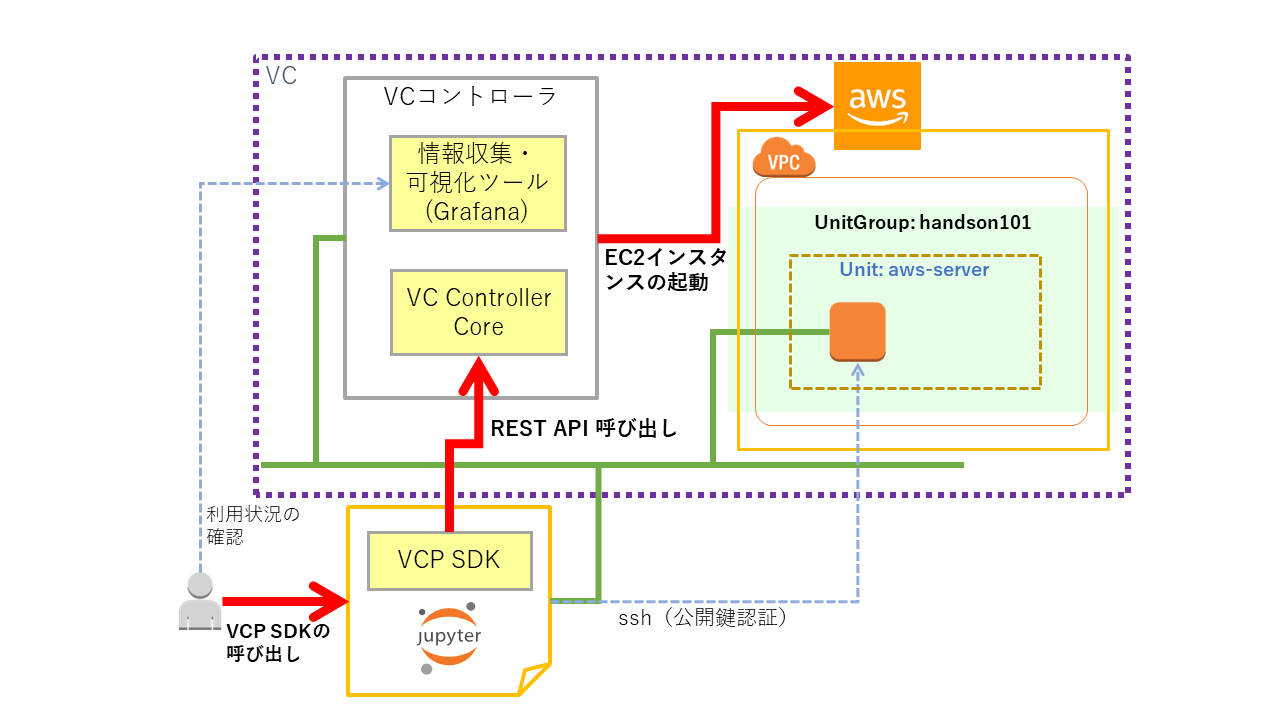
VCP SDKの初期化¶
VCP SDKの初期化を行います。
from common import logsetting
from vcpsdk.vcpsdk import VcpSDK
# VCP SDKの初期化
vcp = VcpSDK(
vcc_access_token, # VCCのアクセストークン
)
上のセルの実行結果がエラーとなり以下のようなメッセージが表示されている場合は、入力されたアクセストークンに誤りがあります。
2019-XX-XX XX:XX:XX,XXX - ERROR - config vc failed: http_status(403)
2019-XX-XX XX:XX:XX,XXX - ERROR - 2019/XX/XX XX:XX:XX UTC: VCPAuthException: xxxxxxx:token lookup is failed: permission deniedこの場合はアクセストークンの入力からやり直してください。
vcpからは UnitGroup の管理(作成、情報取得)や VCP SDK自体に関する情報取得を行うことができます。例えば、次のセルを実行するとUnitGroupの一覧が表示されます。
まだUnitGroupを作成していないので、ヘッダー以外はなにも表示されないはずです。
# UnitGroupの一覧を DataFrame で表示する
vcp.df_ugroups()
次のセルを実行すると VCP SDK と VCコントローラのバージョンが表示されます。
vcp.version()
UnitGroupの作成¶
handson101という名前の UnitGroup を作成します。
# UnitGroupの作成
unit_group = vcp.create_ugroup(
'handson101' # UnitGroupの名前
)
作成したUnitGroupの状態を表示してみます。
UnitGroup の名前が
handson101であることと、その状態がRUNNINGであることなどが確認できるはずです。
print(unit_group)
UnitGroupの一覧を表示してみます。
# UnitGroupの一覧を DataFrame で表示する
vcp.df_ugroups()
UnitGroupの状態を確認する¶
UnitGroupに属している Unit の一覧を表示します。
まだ、このUnitGroupでは Unit を作成していないのでヘッダー以外は何も表示されません。
# Unitの一覧を DataFrame で表示する
unit_group.df_units()
UnitGroupに属しているVCノードの一覧を表示します。
まだVCノードが存在していないので何も表示されません。
unit_group.df_nodes()
VCノードのspecを指定する¶
Unitを構成するVCノードがどのような設定であるかを指定するためのオブジェクトとしてVCP SDKではspecオブジェクトを用意しています。VCP SDKの利用者はspecオブジェクトのプロパティを設定することで Unitに起動するVCノードの設定内容を定義することができます。
specオブジェクトの設定項目の例を以下に示します。
- 仮想マシンのインスタンスタイプ
- m5.large, c5.large, ...
- 仮想マシンのルートボリュームサイズ(GiB)
- 仮想マシンに割り当てるプライベートIPアドレス
- Unit内に作成するVCノードの数
設定できる項目はクラウドプロバイダ(aws, azure, ...)毎に異なります。
flavor の内容を確認する¶
specオブジェクトの全てのパラメータを毎回設定するのは煩雑になるので典型的な構成のパラメータセットを事前に定義しています。事前に定義したspecパラメータセットのことを VCP SDKでは flavorと呼んでいます。specに設定できるパラメータはクラウドプロバイダ毎に異なるので flavorの定義もクラウドプロバイダ毎に行っています。
次のセルを実行すると aws用に定義している flavor の一覧が表示されます。
vcp.df_flavors('aws')
spec オブジェクトを作成する¶
specオブジェクトを作成します。specオブジェクトを作成するにはプロバイダとflavorを指定します。ここでは以下の値を指定します。
- プロバイダ:
aws - flavor:
small
spec = vcp.get_spec('aws', 'small')
作成したspecの設定内容を確認してみます。
instance_typeパラメータにflavorの指定と対応するEC2インスタンスタイプm4.largeが設定されていることが確認できるはずです。volume_size,volume_typeについてもそれぞれflavorと対応する値が設定されます。
print(spec)
specに対しては flavorで指定するだけではなく個々のパラメータを直接指定することもできます。例えば、以下のようなものが指定できます。
- num_nodes
- Unit内に作成するVCノードの数: デフォルト=1
- ip_addresses
- VCノードに割り当てるプライベートIPアドレスのリスト
- このパラメータを指定しない場合は利用可能なアドレスが自動的に割り当てられる
- instance_type
- Amazon EC2のインスタンスタイプ
- flavorで設定されているもの以外を利用したい場合に指定する
- volume_size
- Amazon EC2インスタンスのルートボリュームに割り当てるサイズ(GiB)
- flavorで設定されているもの以外を利用したい場合に指定する
- volume_type
- Amazon EC2インスタンスのルートボリュームのEBSタイプ
- flavorで設定されているもの以外を利用したい場合に指定する
試しに volume_sizeを指定してみます。
spec.volume_size = 15
指定した値がspecの設定に反映されていることを確認してみます。
print(spec)
volume_sizeの値が指定した値に変更されています。
sshの鍵ファイルを設定する¶
VCノードにsshでログインするためには事前に公開鍵認証の鍵を登録する必要があります。そのための設定をここで行います。
VCノードに登録する公開鍵認証の公開鍵のパスを次のセルで指定してください。
import os
ssh_public_key = os.path.expanduser('~/.ssh/id_rsa.pub')
指定した公開鍵を spec に設定します。
spec.set_ssh_pubkey(ssh_public_key)
sshの公開鍵に関する設定がspecに反映されたことを確認してみます。次のセルを実行するとparamsのeのAUTHORIZED_KEYSに値が設定されていることが確認できます。
print(spec)
後でVCノードにログインする際にsshの秘密鍵も必要になるので、ここで設定しておきます。次のセルで秘密鍵のパスを指定してください。
ssh_private_key = os.path.expanduser('~/.ssh/id_rsa')
公開鍵と秘密鍵が正しいペアであることをチェックします。次のセルを実行してエラーにならないことを確認してください。
!grep -q "$(ssh-keygen -y -f {ssh_private_key})" {ssh_public_key}
Unitの作成とVCノードの起動¶
Unitを作成します。Unitを作成すると同時に VCノード(ここでは Amazon EC2インスタンス)が起動します。
処理が完了するまで1分半~2分程度かかります。
# Unitの作成(同時に VCノードが作成される)
unit = unit_group.create_unit(
'aws-server2', # Unit名の指定
spec
)
UnitGroupに属しているUnitの一覧表示を行い、Unitが作成されていることを確認します。
# Unitの一覧を DataFrame で表示する
unit_group.df_units()
UnitGroupに属しているVCノードの一覧表示を行い、VCノードが起動していることを確認します。VCノードが正常に起動していることは node_state の表示が RUNNINGになっていることで確認できます。
# VCノードの一覧を DataFrame で表示する
unit_group.df_nodes()
ここでは VCノードの起動が完了するまで待ち合わせるモードでUnitの作成を行いましたが、非同期処理でUnit, VCノードの作成を行うこともできます。create_unit()のwait_forパラメータにFalseを指定すると非同期モードでのUnit, VCノードの作成が行えます。
unit = unit_group.create_unit('aws-server', spec, wait_for=False)非同期モードでUnitを作成した場合にUnitやVCノードが起動したことを確認するには、以下に示す方法で状態取得を行ってください。
unit_group.df_units()- Unitの一覧表示の
unit_stateの項目で Unitの状態を確認できます - 起動中は
BOOTING、起動が完了して実行中になるとRUNNINGと表示されます
- Unitの一覧表示の
unit.df_nodes(),unit_group.df_nodes()- VCノードの一覧表示の
node_stateの項目で VCノードの状態を確認できます - 起動中は
BOOTING、起動が完了して実行中になるとRUNNINGと表示されます
- VCノードの一覧表示の
非同期モードでUnit作成を行った場合でも、以下のメソッドを利用することで後からVCノード起動の待ち合わせを行うことができます。
unit_group.wait_unit_applied(unit_name)- unit_nameで指定されたUnitの状態が
RUNNINGまたはERRORになるのを待ちます
- unit_nameで指定されたUnitの状態が
疎通確認¶
起動した VCノードに対してpingを行ってみます。
まずUnitGroup内で起動しているVCノードに割り当てられているプライベートIPアドレスの値を取得して変数 ip_addressに格納します。
# unit_group.find_ip_addresses() は UnitGroup内の全VCノードのIPアドレスのリストを返します
ip_address = unit_group.find_ip_addresses(node_state='RUNNING')[0] # 今は1つのVCノードのみ起動しているので [0] で最初の要素を取り出す
print(ip_address)
実際に ping を行ってみます。
Codeセルで先頭に
!をつけるとシェルコマンドが実行できます。また{}で囲むことで Python の変数参照やコードの実行に置き換えることができます。詳しくは「IPython Documentation」などを参照してください。
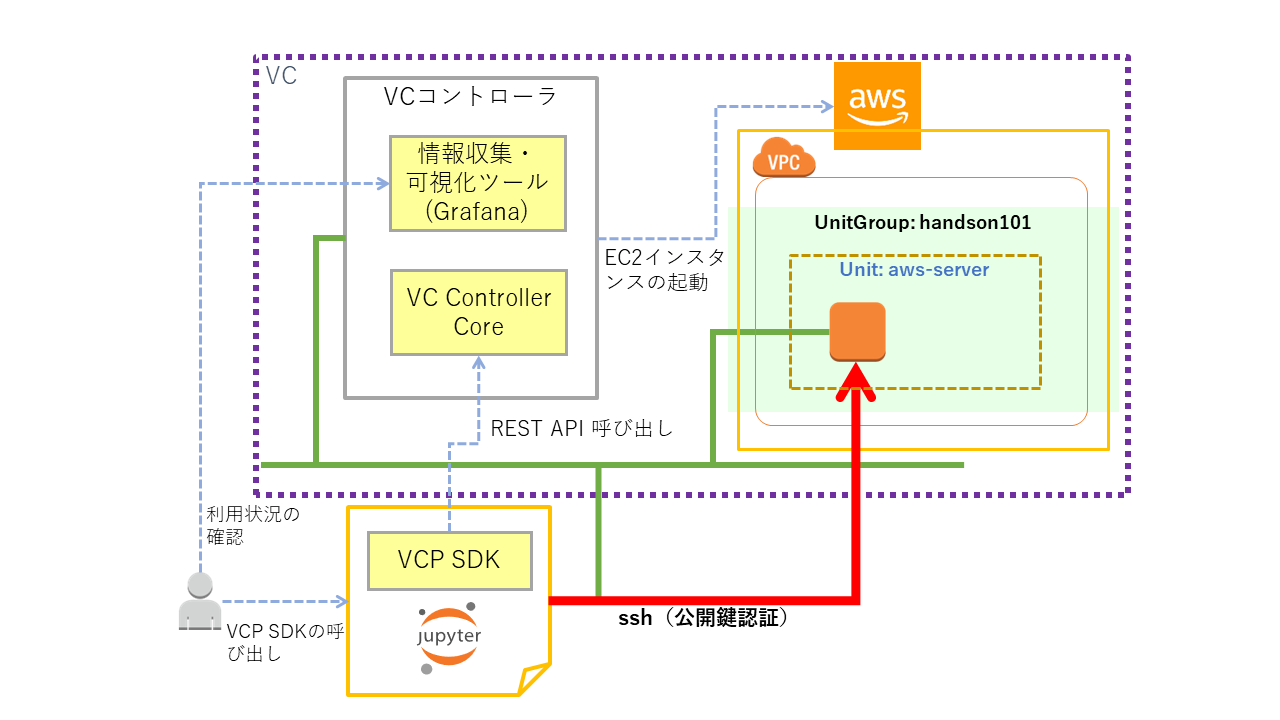
まず、ログインする前に ~/.ssh/known_hosts のホストキーを更新します。
!touch ~/.ssh/known_hosts
# ~/.ssh/known_hosts から古いホストキーを削除する
!ssh-keygen -R {ip_address}
# ホストキーの登録
!ssh-keyscan -H {ip_address} >> ~/.ssh/known_hosts
ls -la を実行してみます。
!ssh -i {ssh_private_key} -l root {ip_address} /bin/ls -la
VCノードにsshでログインするにはsshの引数に以下の指定が必要となります。
- sshの identity ファイル(-i)
specオブジェクトに設定した公開鍵に対応する秘密鍵
- ユーザ名(-l)
root
- ログイン先のIPアドレス
sshのオプションを毎回指定するのも煩雑なので変数に設定しておきます。
ssh_opts = f"-i {ssh_private_key} -l root"
VCノードに対してuname -a, df -h などを実行してみます。
!ssh {ssh_opts} {ip_address} uname -a
!ssh {ssh_opts} {ip_address} df -h
情報収集・可視化ツールでVCノードの利用状況を確認する¶
VCPではVCノードの利用状況(CPU負荷、メモリ使用量、ネットワーク)を確認するための情報収集・可視化ツールとしてGrafanaのダッシュボードを提供しています。
Grafanaへのログイン¶
以下のセルを実行して Grafana ダッシュボードを開いてください。
最初にログイン画面が表示されるので ユーザ名、パスワードにそれぞれ admin, adminを入力してください。
vcc_ctr = vcp.vcc_info()['host']
http_host = vcc_ctr.split(':')[0]
grafana_url = "https://{}/grafana/d/vcp/vcp-metrics?refresh=5s".format(http_host)
print(grafana_url)


VCノードに負荷をかけるために、アプリケーションコンテナで stress コマンドを実行します。
# 60秒間だけ CPU x 2 とメモリ 128 MB を消費する
!ssh {ssh_opts} {ip_address} \
/usr/local/bin/docker run -td --rm --name stress-0 polinux/stress \
stress --cpu 2 --io 1 --vm 2 --vm-bytes 128M --timeout 60s --verbose
# 60秒間だけ CPU x 2 とメモリ 128 MB を消費する (2回目)
!ssh {ssh_opts} {ip_address} \
/usr/local/bin/docker run -td --rm --name stress-1 polinux/stress \
stress --cpu 2 --io 1 --vm 2 --vm-bytes 128M --timeout 60s --verbose
VCノードのスケールアウト、スケールイン¶
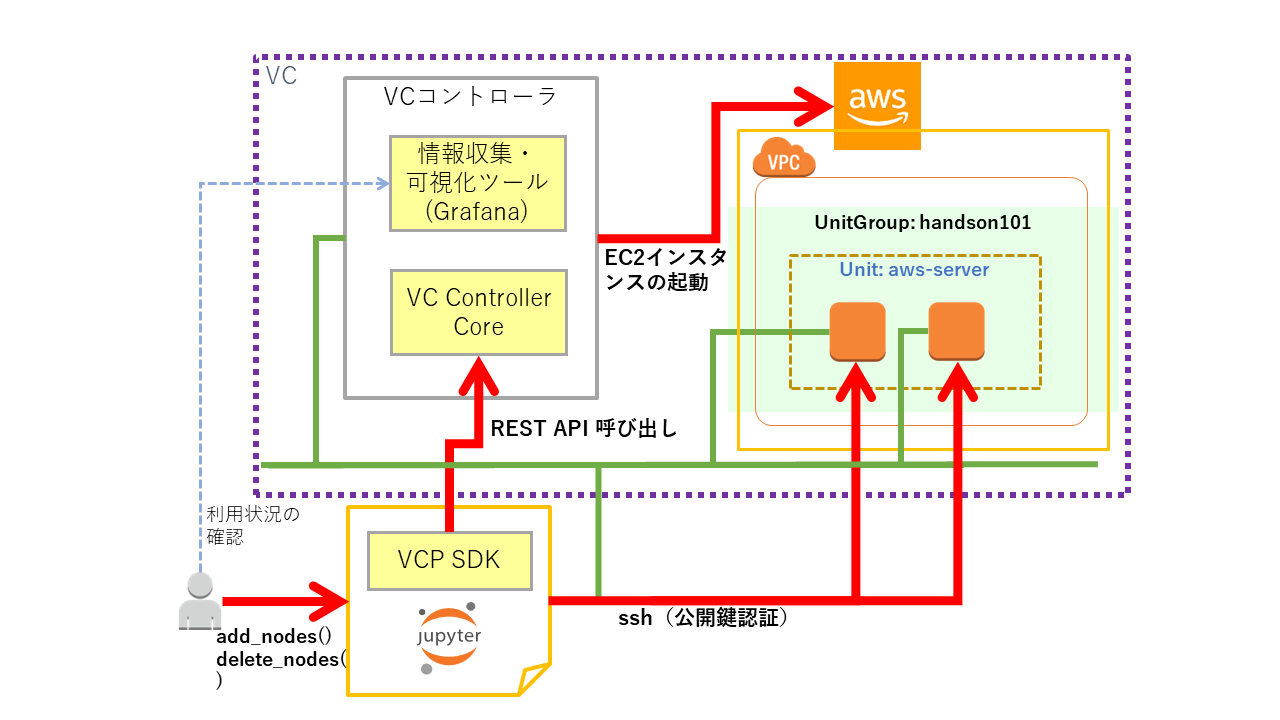
VCノードのスケールアウト¶
Unitには specオブジェクトに指定されている設定と同一の VCノードを作成する機能があります。その機能を利用して Unit にVCノードを追加してみます。
まず、現在のVCノードの状況を確認しておきます。
# VCノードの一覧を DataFrame で表示する
unit.df_nodes()
Unit に VCノードを追加するにはunitオブジェクトに対して add_nodes() を呼び出します。次のセルを実行するとUnitに VCノード が追加されます。
VCノード の起動には 1分半~2分程度かかります。
unit.add_nodes()
add_node()を呼び出すことで追加されるVCノードの数はデフォルトでは1ですが、パラメータnum_add_nodesを設定することで追加するVCノード数を変更することが出来ます。例えば3ノードを追加するには以下のような指定を行います。
unit.add_nodes(num_add_nodes=3)また、追加するVCノードのIPアドレスを指定する場合は、以下のような指定を行います。
unit.add_nodes(ip_address='172.30.2.30')他にどんなパラメータを指定することが出来るかについては次のセルのように Codeセルの先頭で ? を指定することで確認できます。
?unit.add_nodes
追加したVCノードの状態を確認するために、VCノードの一覧表示をおこなってみます。
unit.df_nodes()
起動している全てのVCノードに対して ping を行ってみます。
# Unit内のVCノードのIPアドレスのリストを取得する
ip_address = unit.find_ip_addresses(node_state='RUNNING')
print(ip_address)
# それぞれのIPアドレスに対して pingコマンドを実行する
for address in ip_address:
!ping -c 5 {address}
print()
VCノードを追加したので ~/.ssh/known_hosts を更新します。
for address in ip_address:
# ~/.ssh/known_hosts から古いホストキーを削除する
!ssh-keygen -R {address}
# ホストキーの登録
!ssh-keyscan -H {address} >> ~/.ssh/known_hosts
追加で起動した VCノード は同じ Unit に属しているため同じ構成(cpu, memory, disk)になっています。そのことを確認するために、sshでログインして以下のコマンドを実行してみます。
- カーネルバージョン
- uname -a
- CPU
- cat /proc/cpuinfo
- メモリ量
- free
- ディスク容量
- df -h
ただし aws では同じインスタンスタイプに複数種類の CPU が混在していることがあり CPU が微妙に異なることがあります。
for address in ip_address:
print(address + ':')
!ssh {ssh_opts} {address} uname -a
print()
for address in ip_address:
print(address + ':')
!ssh {ssh_opts} {address} cat /proc/cpuinfo | grep 'model name'
print()
for address in ip_address:
print(address + ':')
!ssh {ssh_opts} {address} free
print()
for address in ip_address:
print(address + ':')
!ssh {ssh_opts} {address} df -h
print()
先程と同様に、負荷をかけるためにそれぞれのVCノードでアプリケーションコンテナによる stress コマンドの実行を行います。
for idx, address in enumerate(ip_address):
# 60秒間だけ CPU x 2 とメモリ 128 MB を消費する
!ssh {ssh_opts} {address} \
/usr/local/bin/docker run -td --rm --name stress-{idx} polinux/stress \
stress --cpu 2 --io 1 --vm 2 --vm-bytes 128M --timeout 60s --verbose
Grafana で利用状況を確認してみます。
VCノードのスケールイン¶
現在Unitには2つのVCノードがありますが、そのうちの一つを削除してみます。
まず、現在のVCノードの状況を確認しておきます。
# VCノードの一覧を DataFrame で表示する
unit.df_nodes()
Unit から VCノードを削除するにはオブジェクトunitに対して delete_nodes() を呼び出します。
複数の VCノード のうちどのVCノード を削除するかを引数で指定することができます。ここではip_addressパラメータを指定してVCノードに割り当てられている IPアドレスで VCノードを特定します。
VCノードを特定するパラメータが指定されなかった場合は削除対象となる VCノードは VCP SDK によって自動的に選択されます。
VCノードを特定するための他のパラメータに指定方法については次のセルを実行すると表示される情報で確認してください。
?unit.delete_nodes
では実際にVCノードを削除します。まず削除対象とするVCノードのIPアドレスを確認します。スケールアウトの節で追加したVCノードのIPアドレスを指定することにします。
# 削除対象とするVCノードの IPアドレスを表示
print(ip_address[-1]) # 後から追加した VCノード を削除対象とする
次のセルを実行するとUnit からVCノードが削除され、対応するAWS EC2インスタンスも削除されます。
VCノード の削除には 1分~2分程度かかります。
# VCノードの削除
unit.delete_nodes(
ip_address=ip_address[-1] # IPアドレスで削除対象を指定する
)
Unit内のVCノードの一覧を確認してみます。VCノードが減っていることが確認できるはずです。
unit.df_nodes()
先ほど取得した2つのVCノードのIPアドレスに対して ping を行ってみます。
削除されている VCノード に対する ping が失敗するので、次のセルは必ずエラーになるはずです。
for address in ip_address:
!ping -c 5 {address}
別のクラウドでVCノードを起動する¶
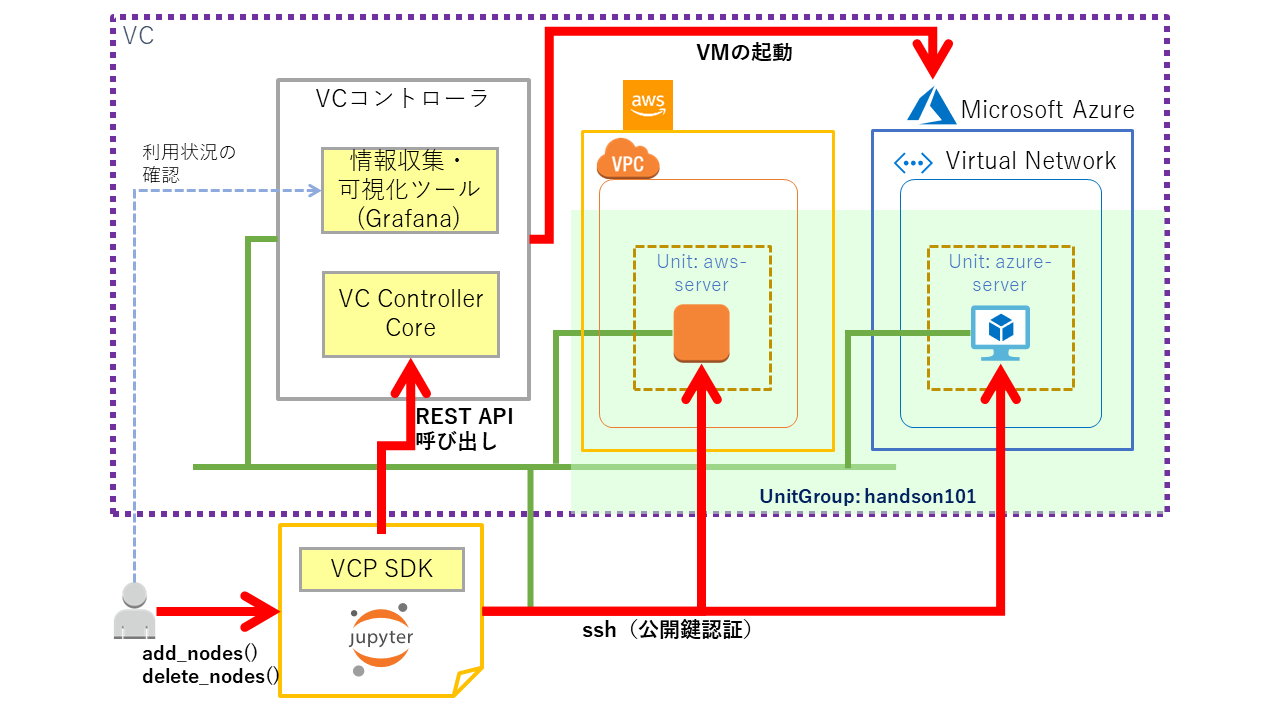
Unit の追加¶
先程とは異なる構成のVCノードを追加するので、新たな Unit を作成します。
VCノードのspecを指定する¶
AWSの場合と同様 spec オブジェクトを作成します。
AWSの場合からの変更点は、specの作成等で指定するプロバイダ名を、使用するプロバイダのものに変更するだけです。 ここでの具体的な変更箇所は次の2つのAPIの引数になります。
VCPSDK::df_flavors()VCPSDK::get_spec()
VCP SDKで現在使用可能なクラウドプロバイダと、それを使用する際の引数に指定するプロバイダ名の値は以下のとおりです。
| クラウドプロバイダ | プロバイダ名 |
|---|---|
| Amazon EC2 | aws |
| Microsoft Azure | azure |
| Oracle Cloud Infrastructure | oracle |
| さくらのクラウド | sakura |
| VMware vSphere | vmware |
ここでは、Microsoft Azure でVCノードを作成します。
下記の 'azure' を指定した箇所を変更することで、他のプロバイダでも同様の操作をすることができます。
まず最初に、Microsoft Azure 用に定義している flavor の内容を確認します。
vcp.df_flavors('azure')
続いて、以下のパラメータを指定して specオブジェクトを作成します。
- プロバイダ:
azure - flavor:
medium
spec_azure = vcp.get_spec('azure', 'medium')
作成したspec_azureの設定内容を確認してみます。
print(spec_azure)
指定した flavorに対応する vm_size, disk_size_gb などが設定されていることが確認できます。
sshの公開鍵設定¶
VCノードに登録するsshの公開鍵を spec_azureに設定します。先ほど aws 向けのspecに設定したのと同じ値を指定しています。
spec_azure.set_ssh_pubkey(ssh_public_key)
specの設定内容を確認する¶
spec_azureの設定内容を確認してみます。
print(spec_azure)
aws向けに最初に作成した specオブジェクトとspec_azureとの差分を確認してみます。
specオブジェクトの内部では aws はinstance_type、azure はvm_sizeなどそれぞれのクラウドプロバイダに応じたパラメータが設定されていることが確認できます。
from difflib import unified_diff
import sys
sys.stdout.writelines(unified_diff(
str(spec).splitlines(True),
str(spec_azure).splitlines(True),
fromfile='aws',
tofile='azure',
))
Unitの作成とVCノードの起動¶
まず作成前のUnitGroup状態を確認しておきます。
from IPython.display import display
# Unitの一覧を DataFrame で表示する
display(unit_group.df_units())
# VCノードの一覧を DataFrame で表示する
display(unit_group.df_nodes())
Unitを作成します。
処理が完了するまでには 2~5分程度かかります。
# Unitの作成(同時に VCノードが作成される)
unit2 = unit_group.create_unit(
'azure-server', # Unit 名
spec_azure # spec オブジェクト
)
Unit作成後の状態を確認します。Unit とVCノードがそれぞれ2つあることが確認できるはずです。VCノード一覧ではそれぞれのVCノードの unit_name が異なることが確認できるはずです。またawsとazureのVCノードには異なるサブネットのIPアドレスが割り当てられていることが確認できます。
# Unitの一覧を DataFrame で表示する
display(unit_group.df_units())
# VCノードの一覧を DataFrame で表示する
display(unit_group.df_nodes())
VCノードを追加したので ~/.ssh/known_hosts を更新します。
for addr in unit_group.find_ip_addresses(node_state='RUNNING'):
!ssh-keygen -R {addr}
!ssh-keyscan -H {addr} >> ~/.ssh/known_hosts
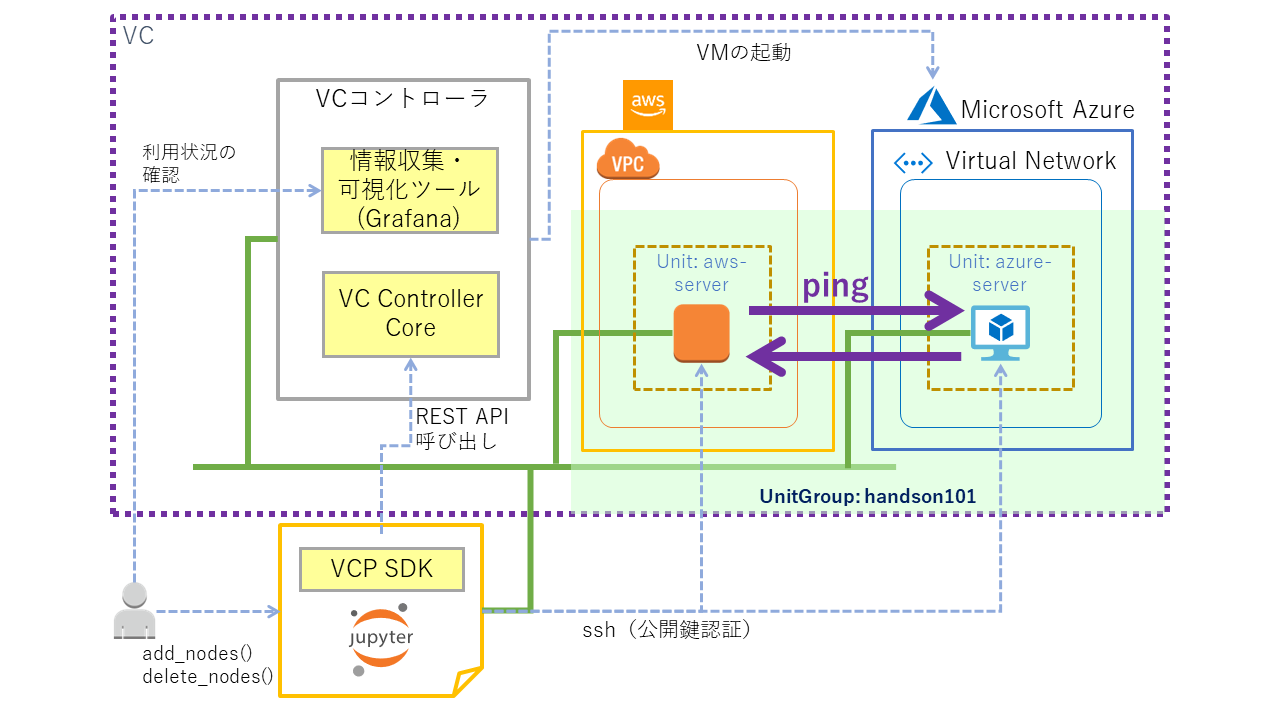
# UnitGroup内にあるVCノードのIPアドレスリストを取得する
ip_address = unit_group.find_ip_addresses(node_state='RUNNING')
VCPでは複数の異なるクラウドを仮想的に一つの計算基盤(仮想クラウド)のように扱える機能を提供しています。そのため異なるクラウド(aws, azure)で起動したVCノードであっても、追加の設定なしに互いに通信することができます。そのことを確認するために、作成した2つの VCノード の一方から他方に対して ping を行ってみます。
# pingを実行するVCノードのIPアドレスを表示する
print(ip_address[0])
print()
!ssh {ssh_opts} {ip_address[0]} \
ping -c 10 {ip_address[1]}
逆方向で同様のことを行ってみます。
# pingを実行するVCノードのIPアドレスを表示する
print(ip_address[1])
print()
!ssh {ssh_opts} {ip_address[1]} \
ping -c 10 {ip_address[0]}
VCノードに ssh でログインして操作する¶
Azureに追加で起動した VCノード は aws とは異なる構成(cpu, memory, disk)になってるはずです。そのことを確認するために、sshでログインして以下のコマンドを実行してみます。
- カーネルバージョン
- uname -a
- CPU
- cat /proc/cpuinfo
- メモリ量
- free
- ディスク容量
- df -h
for address in ip_address:
print(address + ':')
!ssh {ssh_opts} {address} uname -a
print()
for address in ip_address:
print(address + ':')
!ssh {ssh_opts} {address} cat /proc/cpuinfo | grep 'model name'
print()
for address in ip_address:
print(address + ':')
!ssh {ssh_opts} {address} free
print()
for address in ip_address:
print(address + ':')
!ssh {ssh_opts} {address} df -h
print()
最後に先程と同様に、負荷をかけるためにそれぞれのVCノードで stress コマンドを実行します。これまで同様 stressコマンドはアプリケーションコンテナとして実行します。
for unit in unit_group.find_units():
address = unit.find_ip_addresses(node_state='RUNNING')
# 60秒間だけ CPU x 2 とメモリ 128 MB を消費する
!ssh {ssh_opts} {address[0]} \
/usr/local/bin/docker run -td --rm --name stress-{unit.name} polinux/stress \
stress --cpu 2 --io 1 --vm 2 --vm-bytes 128M --timeout 60s --verbose
Grafanaで利用状況を確認してみます。
print(grafana_url)
全てのVCノードを削除する¶
ここまで作成した全てのリソース(UnitGroup, Unit、VCノード)を削除します。この操作を行うことで AWS EC2インスタンスやAzure VMなどのクラウドに作成したリソースが削除されます。
全てのリソースの削除には 4~5分程度かかります。
unit_group.cleanup()
削除後の状態を確認してみます。
# UnitGroupの一覧を DataFrame で表示する
vcp.df_ugroups()